Elasticsearch 是一个基于 Apache Lucene 构建的分布式搜索引擎,广泛应用于全文搜索、日志分析、数据分析等领域。
特点介绍
1. 高性能搜索
- Elasticsearch 通过分布式架构和倒排索引技术,可以进行快速的全文搜索。它能够处理大量数据,并提供低延迟的搜索体验。
- 支持复杂的查询操作,例如精确匹配、模糊匹配、范围查询等,并且能迅速返回结果。
2. 分布式架构
- Elasticsearch 可以水平扩展,即通过增加节点来提升处理能力,支持海量数据存储和高吞吐量操作。
- 它的分布式特性使得数据能够在多个节点上分布,提供高可用性和容错能力。
3. 实时数据处理
- Elasticsearch 支持近实时搜索(NRT),使得数据在写入后几乎可以立即进行搜索。这对于日志分析和监控等场景非常重要。
4. 强大的聚合能力
- 聚合是 Elasticsearch 的一项核心功能,允许用户对搜索结果进行统计分析。例如,可以按时间、地理位置、分类等维度进行数据聚合,帮助用户获取有价值的洞察。
5. 易于扩展
- Elasticsearch 提供了 RESTful API,支持与其他系统进行集成,易于横向扩展。
- 它能够处理不同的数据格式(如 JSON、XML 等)并支持多种编程语言(如 Java、Python、.NET、Go、Node.js 等)。
6. 集成生态
- Elasticsearch 是 Elastic Stack(以前的 ELK Stack)的核心组件之一,Elastic Stack 包括了:
- Logstash:用于数据的收集、处理和转发。
- Kibana:用于数据可视化和展示。
- Beats:轻量级的数据采集工具。
- 这种生态使得日志管理、监控、分析、可视化等任务能够通过集成方式高效完成。
7. 高可用性与容错
- Elasticsearch 自动管理数据的副本,确保数据不会丢失,即使某些节点发生故障,也能继续提供服务。
- 分片和副本的配置允许 Elasticsearch 在集群内进行负载均衡。
8. 支持复杂查询
- 除了基本的全文搜索,Elasticsearch 还支持复杂的查询语言,如:
- 布尔查询:多个条件组合。
- 模糊查询:查找近似匹配。
- 地理位置查询:支持地理空间数据。
- 范围查询:按数值范围、日期范围等过滤数据。
9. 全文检索能力
- Elasticsearch 提供强大的文本分析和全文搜索能力,可以进行词频统计、语法分析、停用词处理等功能,支持对不同语言的文本进行有效的搜索。
10. 支持多种数据类型
- Elasticsearch 支持多种数据类型(例如文本、数字、日期、布尔值、IP 地址、地理位置等),并能够在这些数据上执行高效的查询和分析。
由于这些优势,Elasticsearch 被广泛应用于日志分析、监控、实时搜索、数据分析等场景,尤其在需要处理大规模、高频更新数据的系统中表现优异。
项目实战
环境搭建
我们在/root目录下创建elasticsearch目录以及子目录config 、plugins 、config
当然这是为了做演示和测试直接在root目录下创建,在正式环境中和开发环境中我们应该做好持久化数据文件归类,以便于方便查找和管理。
创建目录以及赋予文件夹权限
mkdir /root/elasticsearch/config -p
mkdir /root/elasticsearch/plugins -p
mkdir /root/elasticsearch/config -p
chmod 777 /root/elasticsearch/config
chmod 777 /root/elasticsearch/plugins
chmod 777 /root/elasticsearch/plugins
在config目录下创建我们的配置文件
vi /root/elasticsearch/config/elasticsearch.yml
配置内容
network.host: 0.0.0.0
network.bind_host: 0.0.0.0 #外网可访问
http.cors.enabled: true
http.cors.allow-origin: "*"
xpack.security.enabled: true # 开启验证
xpack.security.transport.ssl.enabled: false # 开启https
容器运行
这里我们使用50006作为暴露端口,single-node作为单实例模式方便运行测试,es版本定为8.2.3
docker stop elasticsearch
docker rm elasticsearch
docker run --name elasticsearch \
-p 50006:9200 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms1g -Xmx2g" \
-v /root/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /root/elasticsearch/data:/usr/share/elasticsearch/data \
-v /root/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:8.2.3
设置es初始密码
docker exec -it elasticsearch /bin/bash
bin/elasticsearch-setup-passwords interactive
#user: elastic
#password: 123456
创建运维账号
docker exec -it elasticsearch /bin/bash
bin/elasticsearch-users useradd logadmin
增加授权
docker exec -it elasticsearch /bin/bash
bin/elasticsearch-users roles -a superuser logadmin
bin/elasticsearch-users roles -a kibana_system logadmin
登录es后台进行查看
http://localhost:50006/
此时会提示输入账号密码,成功验证后网页中就会提示如下提示,其中就有我们es的版本信息
{
"name": "462d29953899",
"cluster_name": "elasticsearch",
"cluster_uuid": "sMQIN1JgQqmGUG1b3Uy_ow",
"version": {
"number": "8.2.3",
"build_flavor": "default",
"build_type": "docker",
"build_hash": "9905bfb62a3f0b044948376b4f607f70a8a151b4",
"build_date": "2022-06-08T22:21:36.455508792Z",
"build_snapshot": false,
"lucene_version": "9.1.0",
"minimum_wire_compatibility_version": "7.17.0",
"minimum_index_compatibility_version": "7.0.0"
},
"tagline": "You Know, for Search"
}
创建kibana运维面板
同样在root目录创建kibana目录以及config 子目录
mkdir /root/kibana/config -p
创建配置文件
vi /root/kibana/config/kibana.yml
填写配置
这里的localhost可以填写你本地localhost或者局域网或者外网的ip都可以
50006就是上面es暴露的端口,以便于kibana跟es进行通讯
当然你也可以使用docker compose来管理而不是通过ip来访问
server.host: "0.0.0.0"
server.shutdownTimeout: "5s"
elasticsearch.hosts: [ "http://localhost:50006" ]
monitoring.ui.container.elasticsearch.enabled: true
i18n.locale: "zh-CN"
文件提权
chmod 777 /root/kibana/config/kibana.yml
运行容器
50007这里我们作为
ELASTICSEARCH_USERNAME和ELASTICSEARCH_PASSWORD是我们在最上面创建的运维账号创建运维账号
docker stop kibana
docker rm kibana
docker run -d --name kibana \
-p 50007:5601 \
-e "ELASTICSEARCH_HOSTS=http://localhost:50006" \
-e "ELASTICSEARCH_USERNAME=logadmin" \
-e "ELASTICSEARCH_PASSWORD=\"123456\"" \
-v /root/kibana/config/kibana.yml:/usr/share/kibana/config/kibana.yml \
kibana:8.2.3
登录es的kibana运维面板,账号密码就是我们上面设置的logadmin/123456
http://localhost:50007
console控制台
http://localhost:50007/app/dev_tools#/console
登录后台
通过http://localhost:50007进入后台
找到开发工具点击进入控制台
首先我来几个简单的查询指令
添加
向索引 products 添加一条新数据
POST products/_doc
{
"name": "Smartphone",
"price": 699,
"category": "Electronics",
"in_stock": true
}
指定 ID 添加数据
PUT products/_doc/1
{
"name": "Laptop",
"price": 999,
"category": "Electronics",
"in_stock": true
}
查询
查询索引 products 中的所有数据
GET products/_search
{
"query": {
"match_all": {}
}
}
根据条件查询数据
GET products/_search
{
"query": {
"match": {
"name": "laptop"
}
}
}
分页查询
GET products/_search
{
"from": 0,
"size": 10,
"query": {
"match_all": {}
}
}
删除
删除指定ID数据
DELETE products/_doc/1
更新
更新指定ID
POST products/_update/1
{
"doc": {
"price": 899
}
}
添加索引(入门)
PUT products
{
"mappings": {
"properties": {
"name": { "type": "text" },
"price": { "type": "float" },
"category": { "type": "keyword" },
"in_stock": { "type": "boolean" }
}
}
}
添加分词索引
添加分词插件
分词插件有很多,这里我就使用ik分词器
首先进入容器
执行如下指令,版本最好要对应上
bin/elasticsearch-plugin install https://github.com/infinilabs/analysis-ik/releases/download/v8.2.3/elasticsearch-analysis-ik-8.2.3.zip
添加索引
ik_max_word是插件分词器
comma_tokenizer是我们自定义的分词
DELETE /products
PUT /products
{
"settings": {
"analysis": {
"analyzer": {
"ik_max_word": {
"type": "ik_max_word"
},
"comma_analyzer": {
"type": "custom",
"tokenizer": "comma_tokenizer"
}
},
"tokenizer": {
"comma_tokenizer": {
"type": "char_group",
"tokenize_on_chars": [","]
}
}
}
},
"mappings": {
"properties": {
"category": {
"type": "text",
"analyzer": "ik_max_word"
},
"name": {
"type": "text",
"analyzer": "comma_analyzer"
}
}
}
}
提示成功后我们接着添加一些种子数据
POST products/_bulk
{ "index": { "_id": 1 } }
{ "name": "苹果", "price": 699, "category": "苹果手机 绿色 8+128", "in_stock": true }
{ "index": { "_id": 2 } }
{ "name": "苹果", "price": 999, "category": "苹果手机 绿色 8+256", "in_stock": true }
{ "index": { "_id": 3 } }
{ "name": "苹果", "price": 199, "category": "苹果手机 红色 8+128", "in_stock": false }
{ "index": { "_id": 4 } }
{ "name": "苹果", "price": 199, "category": "苹果手机 红色 8+256", "in_stock": false }
商品搜索
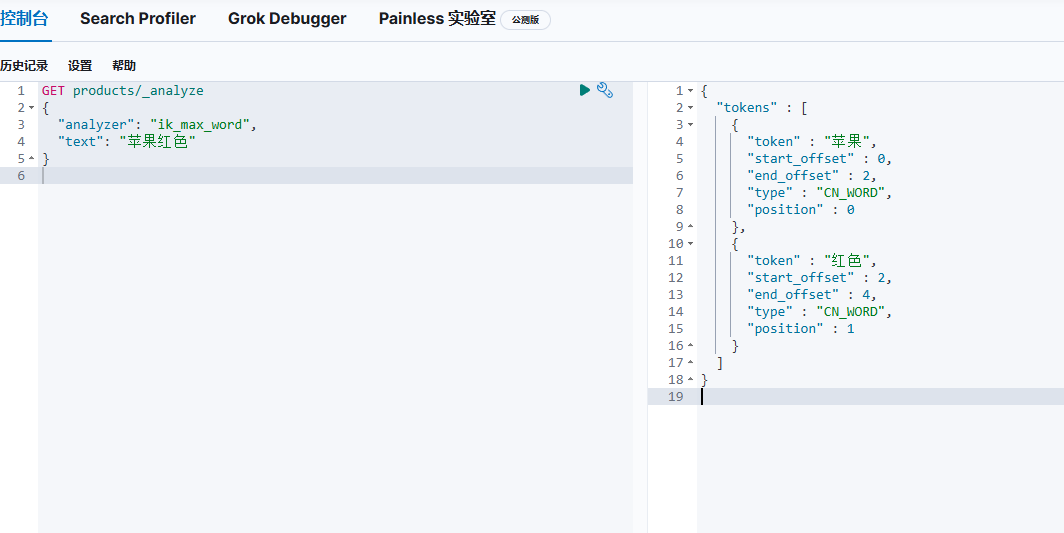
我们可以先获取分词看看我们输入"苹果红色"会出现什么效果
GET products/_analyze
{
"analyzer": "ik_max_word",
"text": "苹果红色"
}
可以看出我们的分词器应用,在右边我们看出"苹果"和"红色"作为了两个分词token
那么当我们把分词结果token放入真实的查询条件中
GET products/_search
{
"query": {
"bool": {
"must": [
{ "match": { "category": "苹果" } },
{ "match": { "category": "红色" } }
]
}
}
}
我们可以看到执行结果,只要是苹果红色产品就搜索出来了
至此,我们的商品基础查询已经完成。
es的强大功能我们只是探索了其一,接下来我们将进行一些代码的实战。

实战代码(java)
添加依赖
<!--es搜索-->
<dependency>
<groupId>co.elastic.clients</groupId>
<artifactId>elasticsearch-java</artifactId>
<version>8.12.2</version>
</dependency>
<dependency>
<groupId>jakarta.json</groupId>
<artifactId>jakarta.json-api</artifactId>
<version>2.0.1</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>8.12.2</version>
</dependency>
配置文件
/**
* es搜索服务配置
*/
@Configuration
public class ElasticsearchClientConfig {
@Value("${spring.elasticsearch.serverUrl}")
private String serverUrl;
@Value("${spring.elasticsearch.apiKey}")
private String apiKey;
@Bean(name = "esV1")
public ElasticsearchClient elasticsearchClient() {
RestClient restClient = RestClient
.builder(HttpHost.create(serverUrl))
.setDefaultHeaders(new Header[]{
new BasicHeader("Authorization", "ApiKey " + apiKey)
})
.build();
RestClientTransport transport = new RestClientTransport(
restClient, new JacksonJsonpMapper());
return new ElasticsearchClient(transport);
}
}
获取分词
@Resource(name = "esV1")
private ElasticsearchClient client;
public List<AnalyzeToken> analyzeText(String indexName, String text) {
try {
if (StringUtils.isBlank(text)) return new ArrayList<>();
// 创建AnalyzeRequest,使用ik_max_word分析器
AnalyzeRequest request = AnalyzeRequest.of(a -> a.text(text) // 传入需要分词的文本
.index(indexName).analyzer("ik_max_word") // 使用ik_max_word分析器
);
// 执行分词分析
AnalyzeResponse response = client.indices().analyze(request);
// 获取分析结果
List<AnalyzeToken> tokens = response.tokens();
return tokens;
} catch (Exception ex) {
log.error("分词异常", ex);
throw new ServiceException("分词异常:" + ex.getMessage());
}
}
添加数据
public void insertData(String indexName, List<Map<String, Object>> dataList,String fieldId) {
try {
List<BulkOperation> bulkOperations = new ArrayList<>();
for (Map<String, Object> data : dataList) {
// 创建 BulkOperation 并添加到列表中
BulkOperation operation = new BulkOperation.Builder().index(idx -> idx.index(indexName) // 替换为您的索引名称
.id(data.get(fieldId).toString()) // 文档ID,指定那个字段名称作为主键
.document(data)) // 文档数据
.build();
bulkOperations.add(operation);
}
// 发送批量请求
BulkResponse response = client.bulk(b -> b.operations(bulkOperations));
// 响应状态
if (response.errors()) {
response.items().forEach(item -> {
if (item.error() != null) {
throw new ServiceException("添加集合失败:" + item.error().reason());
}
});
} else {
//添加成功
}
} catch (Exception ex) {
log.error("添加集合失败:" + indexName, ex);
throw new ServiceException("添加集合失败:" + ex.getMessage());
}
}
查询数据
public SearchItemResultDto searchShop(ShopQuery query) {
int from = (query.getPage() - 1) * query.getSize();
List<AnalyzeToken> analyzeTokens = analyzeText(query.getIndexName(), query.getSearchKey());
SearchItemResultDto data = new SearchItemResultDto();
List<Query> mustConditions = new ArrayList<>();
//关键词
for (AnalyzeToken analyzeToken : analyzeTokens) {
Query filter = Query.of(q -> q.match(m -> m.field("searchName").query(analyzeToken.token())));
mustConditions.add(filter);
}
//地区
if (!StringUtils.isBlank(query.getArea())) {
Query filter = Query.of(q -> q.match(m -> m.field("area").query(query.getArea())));
mustConditions.add(filter);
}
//品牌
if (!StringUtils.isBlank(query.getBrand())) {
Query filter = Query.of(q -> q.match(m -> m.field("brand").query(query.getBrand())));
mustConditions.add(filter);
}
// //品牌首字母
// if (!StringUtils.isBlank(query.getBrandPrefix())) {
// Query filter = Query.of(q -> q.match(m -> m.field("brandPrefix").query(query.getBrandPrefix())));
// mustConditions.add(filter);
// }
// //品目
// if (!StringUtils.isBlank(query.getCategory())) {
// Query filter = Query.of(q -> q.match(m -> m.field("category").query(query.getCategory())));
// mustConditions.add(filter);
// }
BoolQuery boolQuery = BoolQuery.of(b -> b.must(mustConditions));
List<ShopItemDto> results = new ArrayList<>();
// 创建搜索请求
SearchRequest searchRequest = new SearchRequest.Builder().index(ShopItemDto.KEY).query(Query.of(q -> q.bool(boolQuery))).from(from).size(query.getSize()).build();
try {
// 执行搜索请求
SearchResponse<ShopItemDto> response = client.search(searchRequest, ShopItemDto.class);
// 处理搜索结果
for (Hit<ShopItemDto> hit : response.hits().hits()) {
results.add(hit.source());
}
data.setData(results);
data.setTotal(response.hits().total().value());
return data;
} catch (Exception ex) {
log.error("搜索异常", ex);
throw new ServiceException("搜索异常:" + ex.getMessage());
}
}
搜索参数
/**
* @Author:HDW
* @Description: 商品搜索参数
**/
@Data
public class ShopQuery {
/**
* 索引名称
*/
private String indexName;
/**
* 搜索关键词
*/
private String key;
/**
* 实际搜索
*/
private String searchKey;
/**
* 当前页
*/
private int page;
/**
* 分页大小
*/
private int size;
/**
* 品牌
*/
private String brand;
/**
* 品牌首字母
*/
private String brandPrefix;
/**
* 品目id列表
*/
private String category;
/**
* 地区
*/
private String area;
}
结果集
/**
* @Author:HDW
* @Description: 接收商品搜索dto
**/
@Data
public class SearchItemResultDto {
private long total;
private List<ShopItemDto> data = new ArrayList<>();
}
/**
* @Author:HDW
* @Description: 商品搜索dto
**/
@Data
public class ShopItemDto {
public static final String KEY = "product";
@ApiModelProperty("spu标识")
public String spu;
@ApiModelProperty("sku标识")
public String sku;
@ApiModelProperty("产品名称")
public String spuName;
@ApiModelProperty("商品名称")
public String skuName;
@ApiModelProperty("sku规格")
public String spec;
@ApiModelProperty("商品价格")
public double price;
@ApiModelProperty("商品图片")
public String picture;
@ApiModelProperty("商品数量")
public int count;
@ApiModelProperty("搜索名称集合")
public String searchName;
@ApiModelProperty("品牌id")
public String brand;
@ApiModelProperty("品牌首字母")
public String brandPrefix;
@ApiModelProperty("品目id列表")
public String category;
@ApiModelProperty("供应商")
public String supplier;
@ApiModelProperty("地区")
public String area;
}
删除索引数据
public void clearOldData(String indexName) {
try {
DeleteByQueryRequest deleteRequest = new DeleteByQueryRequest.Builder().index(indexName).query(new MatchAllQuery.Builder().build()._toQuery()).build();
DeleteByQueryResponse response = client.deleteByQuery(deleteRequest);
} catch (Exception ex) {
log.error("删除集合失败:" + indexName, ex);
}
}