介绍
Prometheus、Grafana、Node Exporter 和Alertmanager是一组用于监控和可视化系统性能的开源工具。它们通常一起使用,形成一个强大的完整的监控和告警系统。
一般来说,这四个工具一起协作,形成了一个完整的监控和告警系统。Node Exporter用于收集主机级别的指标,Prometheus存储和查询这些指标,Grafana提供可视化界面,而Alertmanager则负责管理和发送告警。整个系统的目标是帮助管理员和开发人员实时了解系统的状态、性能和健康状况,并在必要时采取措施。
Prometheus
Prometheus 是一种开源的系统监控和警报工具。它最初由 SoundCloud 开发,并成为 Cloud Native Computing Foundation(CNCF)的一部分。Prometheus 支持多维度的数据模型和强大的查询语言,使得用户可以轻松地收集和查询各种类型的监控数据。
Grafana
Grafana 是一个开源的数据可视化和监控平台。它提供了丰富的图表和仪表盘,可以将各种数据源的信息可视化展示。Grafana 支持多个数据源,包括 Prometheus、Graphite、InfluxDB 等,因此可以与各种监控系统集成,提供灵活且强大的可视化功能。
Node Exporter
Node Exporter 是一个用于在 Unix/Linux 系统上暴露系统信息的 Prometheus Exporter。它会收集关于系统资源使用情况、性能指标等方面的信息,并将这些信息提供给 Prometheus 进行监控。Node Exporter 通常与 Prometheus 配合使用,以监控主机上的各种系统级别的指标,例如 CPU 使用率、内存使用率、磁盘空间等。
Alertmanager
Alertmanager 是 Prometheus 生态系统中的一个组件,负责处理和管理告警。当 Prometheus 检测到异常或达到某个预定的阈值时,它将生成告警并将其发送到 Alertmanager。Alertmanager 可以进行静默、分组、抑制和路由告警,并将它们发送到不同的接收端,如电子邮件、Slack 等。
预览
我们先看效果
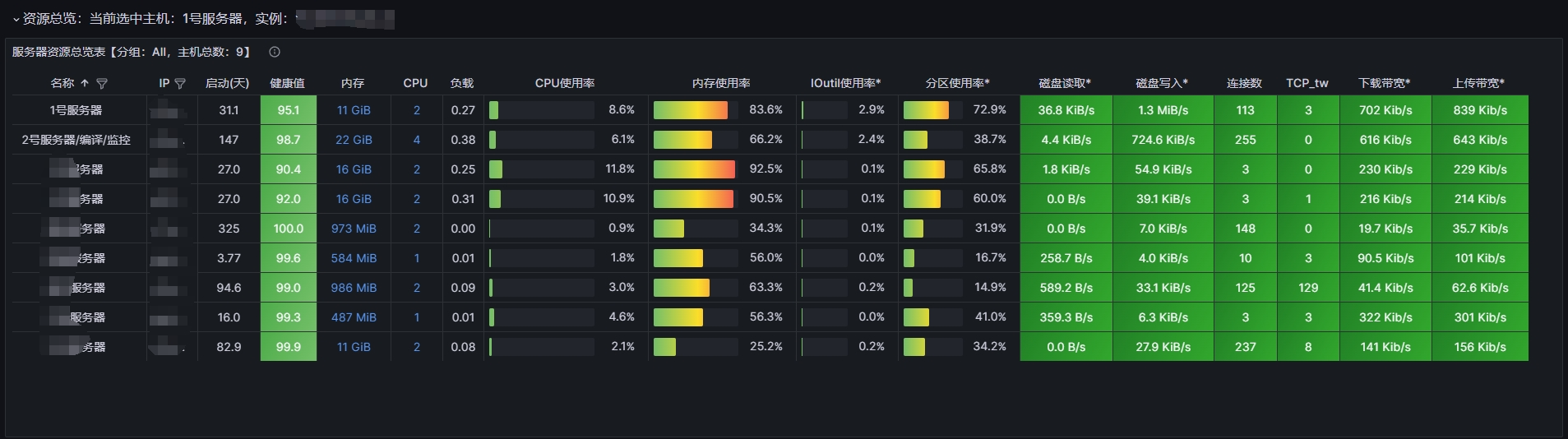
这是grafana面板的局部截图,一个整体系统资源总览,方便我们快速发现问题并检索,这也是我们日常使用最频繁的地点。
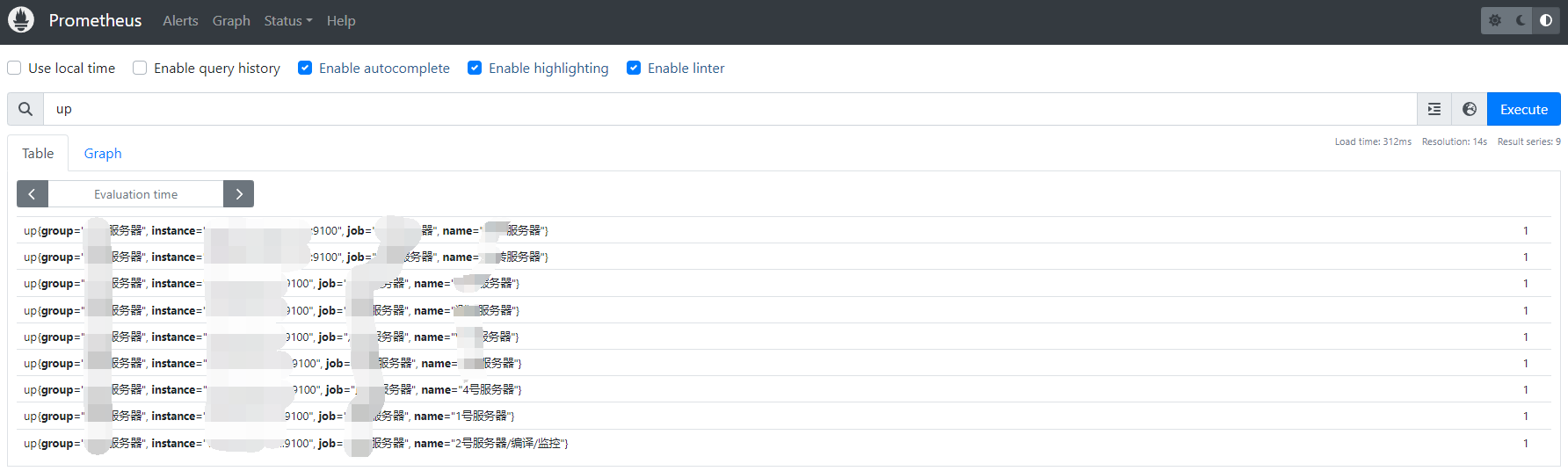
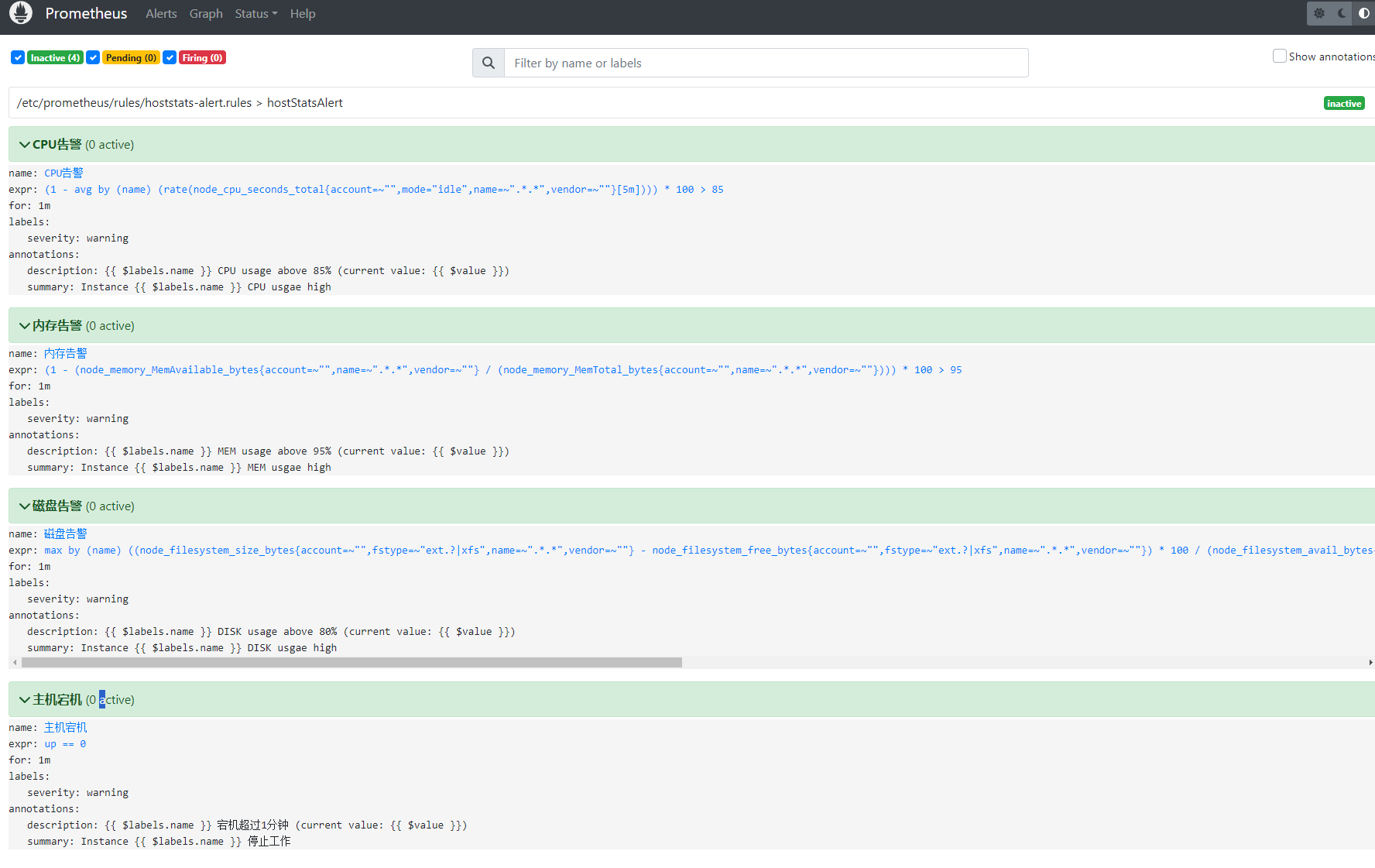
下面是prometheus的局部截图
接下来就是alertmanager的截图,主要是接收prometheus触发的告警,alertmanager负责推送。
最后就是我们的采集器Node Exporter,在宿主机上部署,一般是监听9100端口,访问后可以看到宿主机的各种指标参数。
准备
服务端
Centos7 + Docker
客户端
Centos +可选Docker
安装使用
接下来我们将进行安装和使用,首先是安装我们指标收集器
node Exporter
#arm平台 wget https://github.com/prometheus/node_exporter/releases/download/v1.6.1/node_exporter-1.6.1.linux-arm64.tar.gz tar -xzf node_exporter-1.6.1.linux-arm64.tar.gz cp node_exporter-1.6.1.linux-arm64/node_exporter /usr/local/bin/ #amd平台 wget https://github.com/prometheus/node_exporter/releases/download/v1.6.1/node_exporter-1.6.1.linux-amd64.tar.gz tar -xzf node_exporter-1.6.1.linux-amd64.tar.gz cp node_exporter-1.6.1.linux-amd64/node_exporter /usr/local/bin/ #进程守护 cat > /etc/systemd/system/notdeexporter.service << EOF [Unit] Description=notdeexporter After=network.target network-online.target nss-lookup.target [Service] Type=simple StandardError=journal ExecStart = /usr/local/bin/node_exporter ExecReload=/bin/kill -HUP $MAINPID LimitNOFILE=512000 Restart=on-failure RestartSec=10s [Install] WantedBy=multi-user.target EOF #启动 systemctl daemon-reload systemctl start notdeexporter systemctl enable notdeexporter systemctl status notdeexporter
当我们看到绿色的active (running) 则安装成功。

访问宿主+9100端口既可访问Node Exporter采集的指标数据
prometheus
接下来我们接着安装prometheus,除了Node Exporter,其他的我们都将采用docker进行安装,因为除了Node Exporter安装在客户端上,其他都在服务端上既可。
docker stop prometheusserver docker rm prometheusserver docker run -i --restart=always \ --name prometheusserver \ -p 9000:9090 \ -v /root/prometheus/data:/prometheus-data \ -v /root/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml \ -v /root/prometheus/rules:/etc/prometheus/rules \ -d prom/prometheus --config.file=/etc/prometheus/prometheus.yml --storage.tsdb.path=/prometheus-data/
9000:9090
9090是容器内部端口,9000外部端口作为NGINX代理使用,你也可以直接访问9000端口
/prometheus-data
/prometheus-data 是 prometheus的数据目录
/etc/prometheus/prometheus.yml
/etc/prometheus/prometheus.yml是prometheus主配置
# 抓取规则
global:
scrape_interval: 15s # 抓取间隔
evaluation_interval: 15s # 评估间隔
# 触发规则
rule_files:
- /etc/prometheus/rules/*.rules
# alert告警服务器
alerting:
alertmanagers:
- static_configs:
- targets: ['域名/服务器+端口']
# 监控客户端列表
scrape_configs:
- job_name: "测试服务器"
static_configs:
- targets: ['域名/IP:9100']
labels:
name: "1号服务器"
group: "测试服务器"
- targets: ['域名/IP:9100']
labels:
name: "2号服务器/编译/监控"
group: "测试服务器"
- job_name: "应用服务器"
static_configs:
- targets: ['域名/IP:9100']
labels:
name: "邮件服务器"
group: "应用服务器"
- targets: ['域名/IP:9100']
labels:
name: "测试服务器"
group: "应用服务器"
/etc/prometheus/rules
/etc/prometheus/rules主要是存放告警规则的目录
举例:hoststats-alert.rules
groups:
- name: hostStatsAlert
rules:
- alert: CPU告警
expr: (1 - avg(rate(node_cpu_seconds_total{vendor=~"",account=~"",mode="idle",name=~".*.*"}[5m])) by (name)) * 100 > 85
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {{ $labels.name }} CPU usgae high"
description: "{{ $labels.name }} CPU usage above 85% (current value: {{ $value }})"
- alert: 内存告警
expr: (1 - (node_memory_MemAvailable_bytes{vendor=~"",account=~"",name=~".*.*"} / (node_memory_MemTotal_bytes{vendor=~"",account=~"",name=~".*.*"})))* 100 > 95
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {{ $labels.name }} MEM usgae high"
description: "{{ $labels.name }} MEM usage above 95% (current value: {{ $value }})"
- alert: 磁盘告警
expr: max((node_filesystem_size_bytes{vendor=~"",account=~"",name=~".*.*",fstype=~"ext.?|xfs"}-node_filesystem_free_bytes{vendor=~"",account=~"",name=~".*.*",fstype=~"ext.?|xfs"}) *100/(node_filesystem_avail_bytes {vendor=~"",account=~"",name=~".*.*",fstype=~"ext.?|xfs"}+(node_filesystem_size_bytes{vendor=~"",account=~"",name=~".*.*",fstype=~"ext.?|xfs"}-node_filesystem_free_bytes{vendor=~"",account=~"",name=~".*.*",fstype=~"ext.?|xfs"})))by(name) > 80
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {{ $labels.name }} DISK usgae high"
description: "{{ $labels.name }} DISK usage above 80% (current value: {{ $value }})"
- alert: 主机宕机
expr: up == 0
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {{ $labels.name }} 停止工作"
description: "{{ $labels.name }} 宕机超过1分钟 (current value: {{ $value }})"
当配置完成并启动容器后,访问服务端+9000端口即可访问
主页
是否有触发
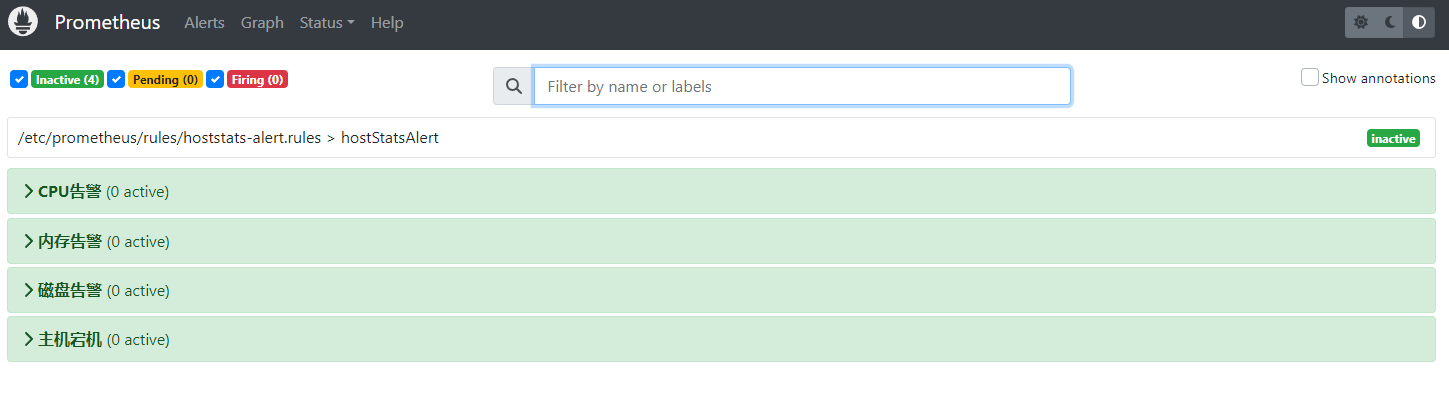
具体规则查看
grafana
docker stop grafanaserver docker rm grafanaserver docker run -i --restart=always \ --name grafanaserver \ -v /root/grafana/config/grafana.ini:/etc/grafana/grafana.ini \ -v /root/grafana/data:/var/lib/grafana \ -p 9001:3000 \ -d grafana/grafana
/etc/grafana/grafana.ini
/etc/grafana/grafana.ini 是grafana的主要配置文件
#内容太多,就不贴出来了,可自行启动容器拷贝一份出来进行修改,这里一般不修改
/var/lib/grafana
/var/lib/grafana是 grafana的持久化数据目录,需要从容器中映射出
温馨提示:这里需要把映射出来的数据目录修改最高权限,否则容器启动后将会出现无法访问的情况
chmod 777 /root/grafana/data
9001:3000
9001:3000 内部端口为3000,我们映射到宿主机端口9001进行访问
访问登录页面需要输入账号密码,默认账号密码admin/admin
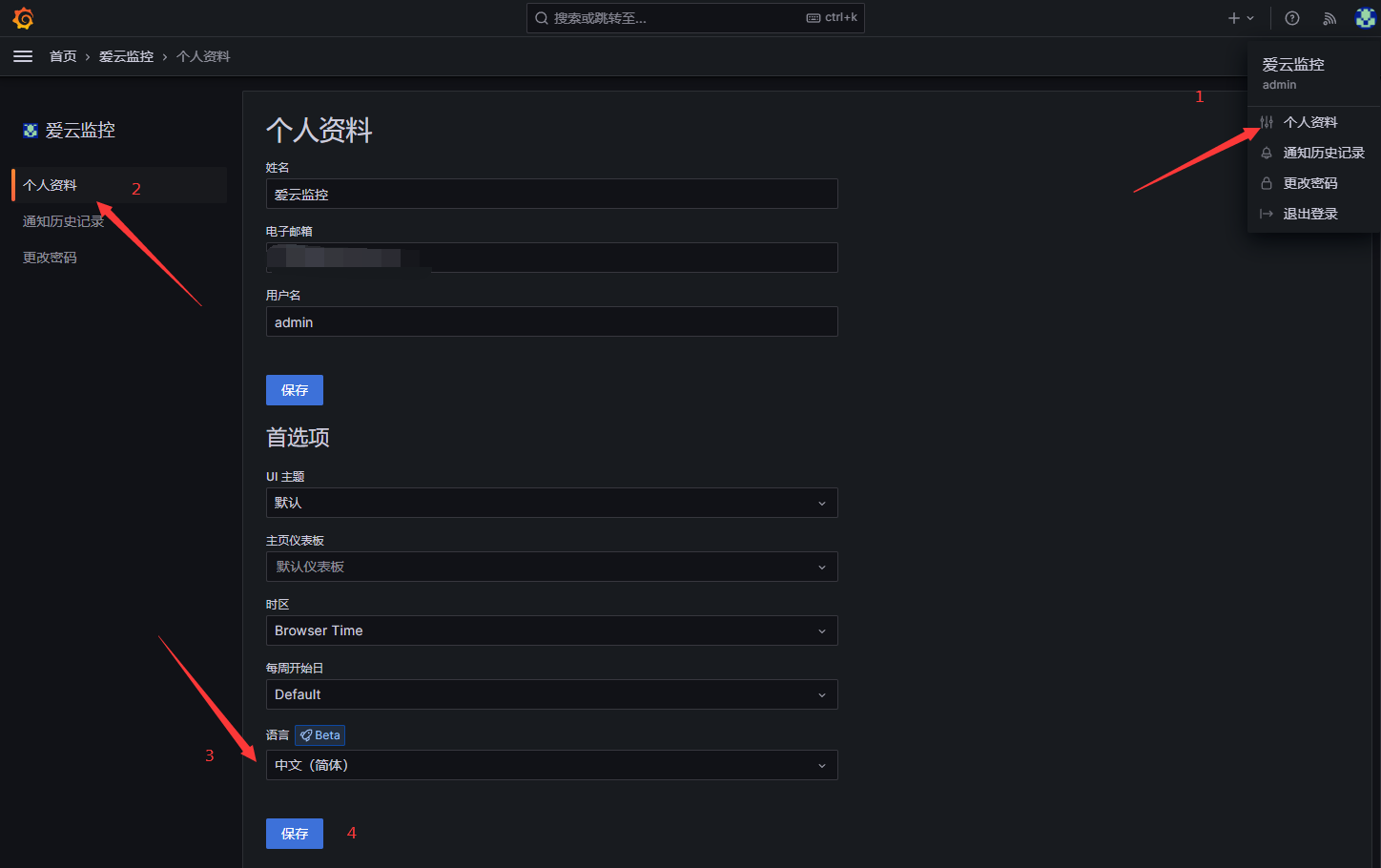
登录后,根据自己的需要我们设置一下系统的语言显示
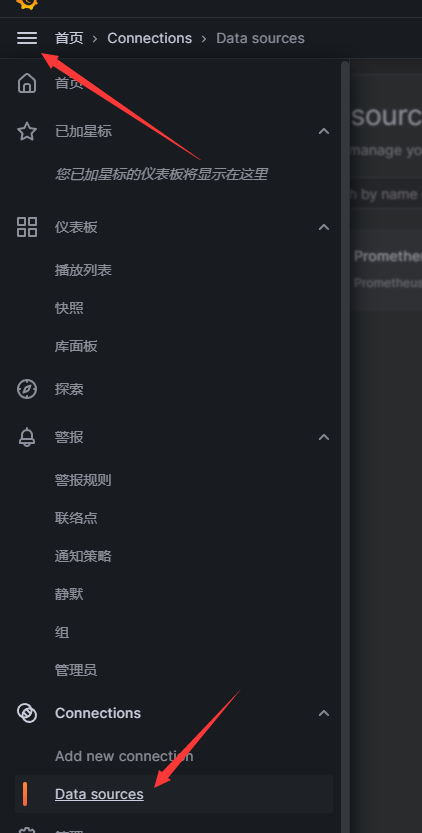
再接着我们接入prometheus汇聚的数据源
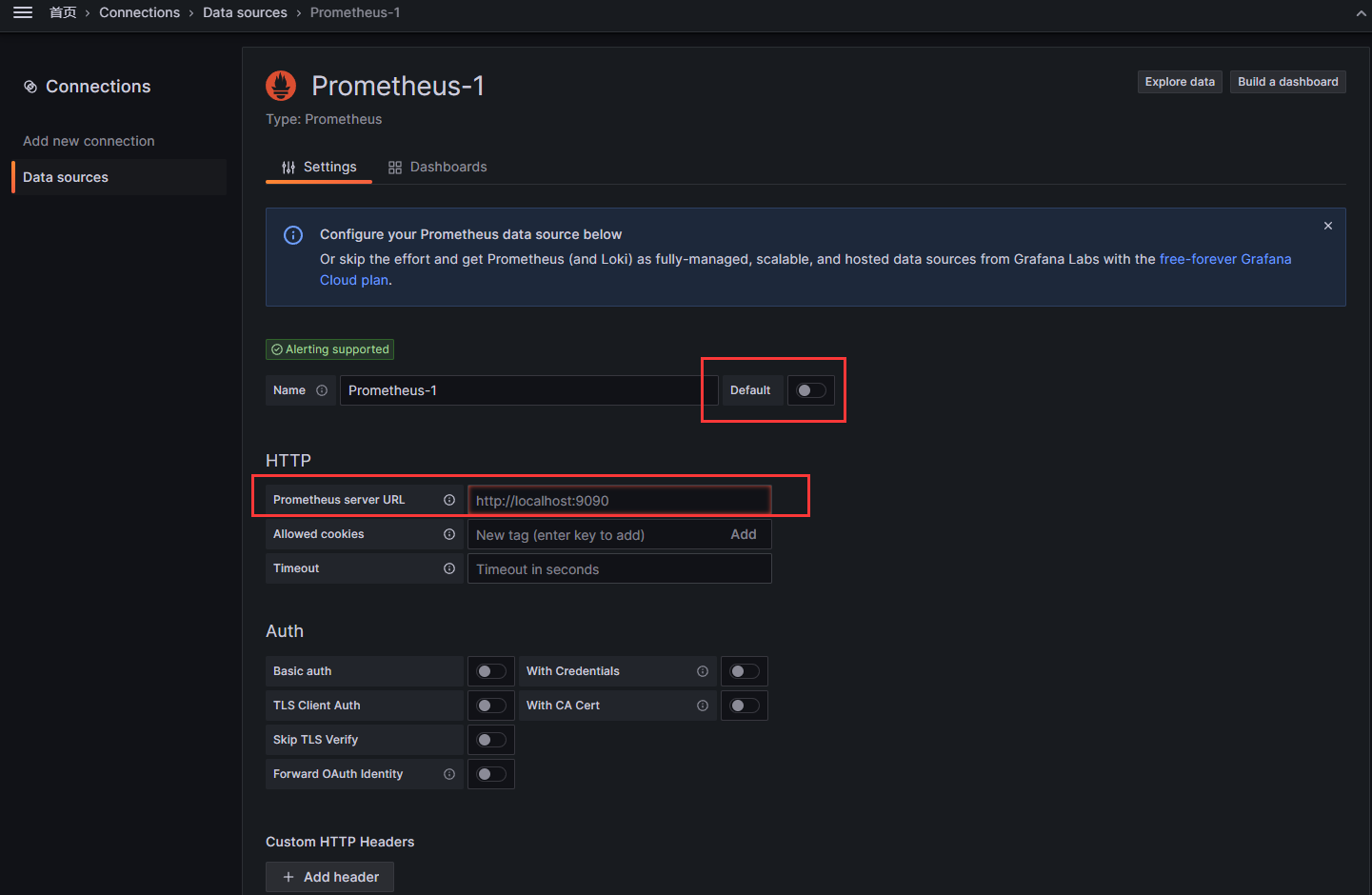
仪表盘=>Connections=>Data sources
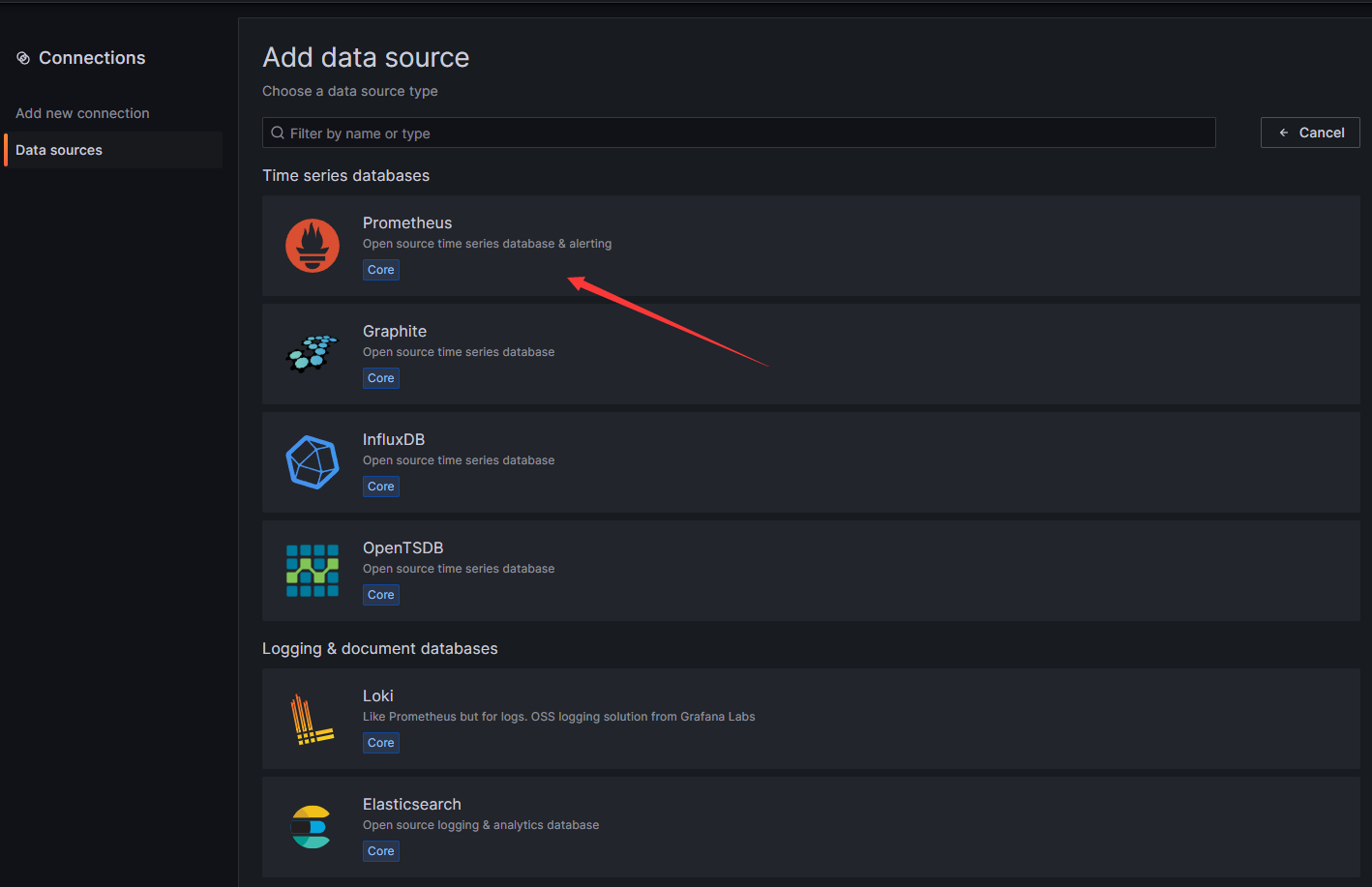
然后点右上角的Add data source ,然后选择第一个Prometheus作为数据源
填写上刚刚部署的Prometheus的地址,并设置为默认数据源,然后拉到最下面保存便接入完成了。
如果有其他特殊需求,填写相应设置即可。
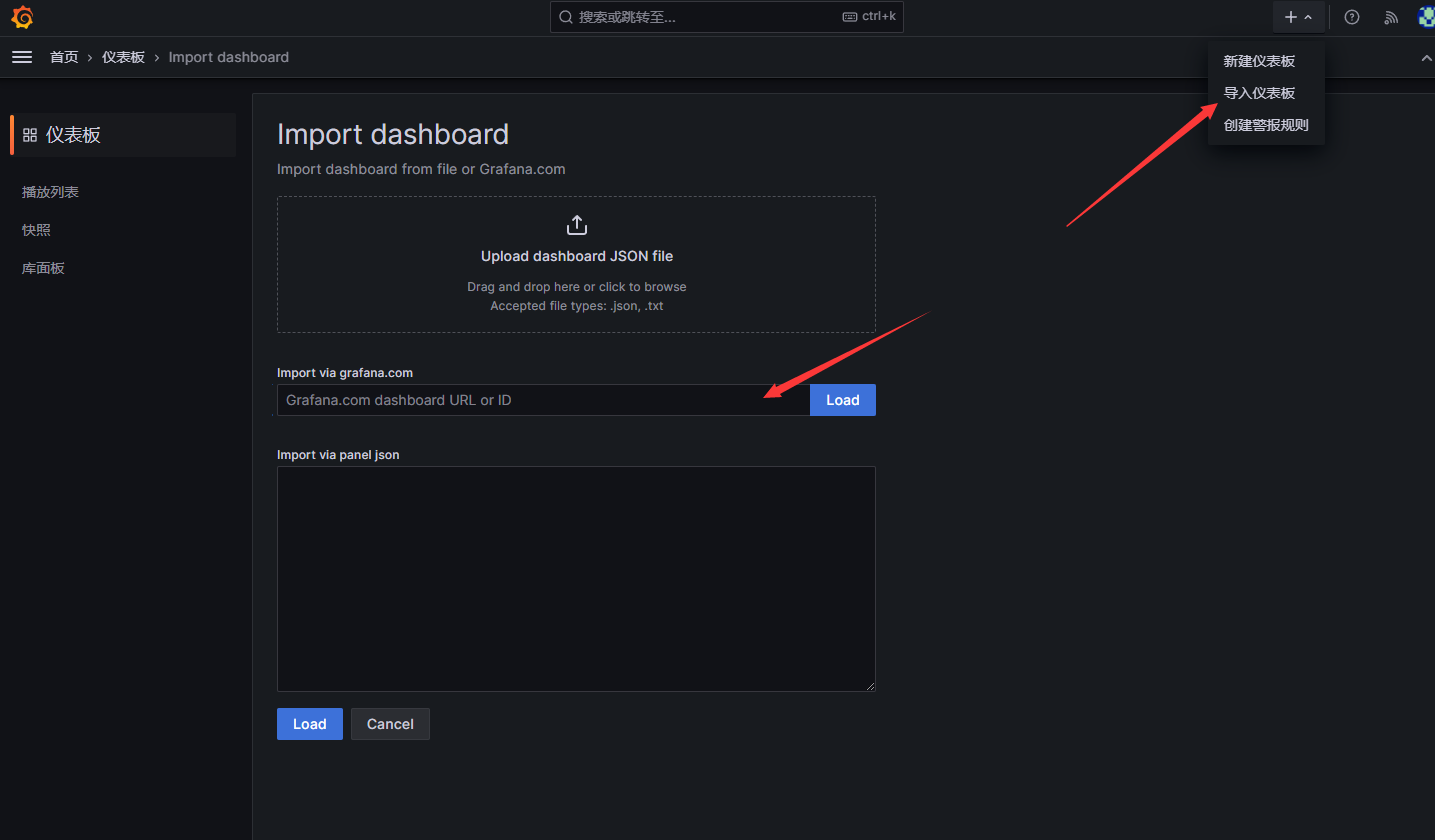
然后接着导入面板,这里提供三个好看的面板,分别是8919,9276,11074
输入后点击Load既可加载面板
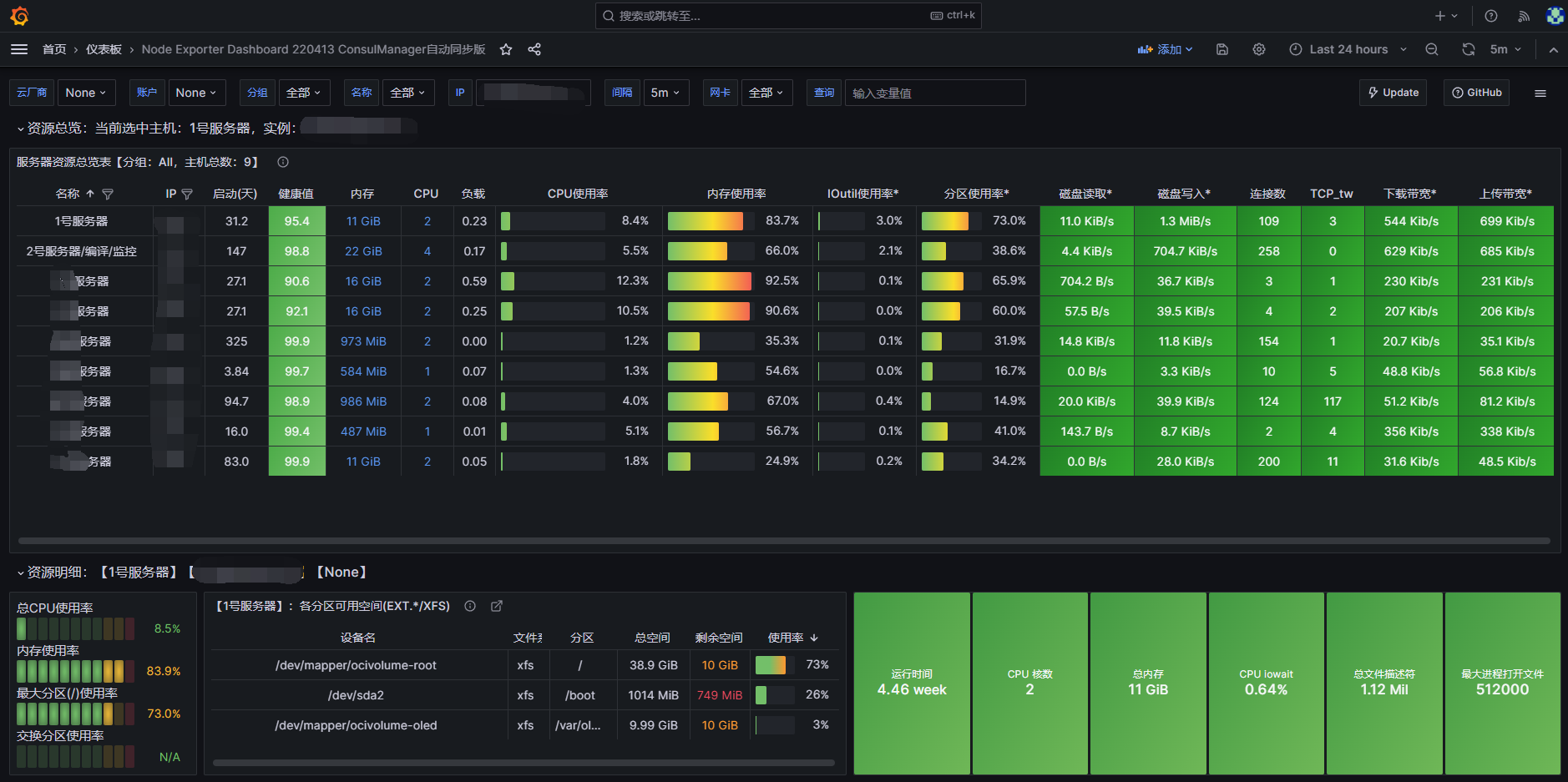
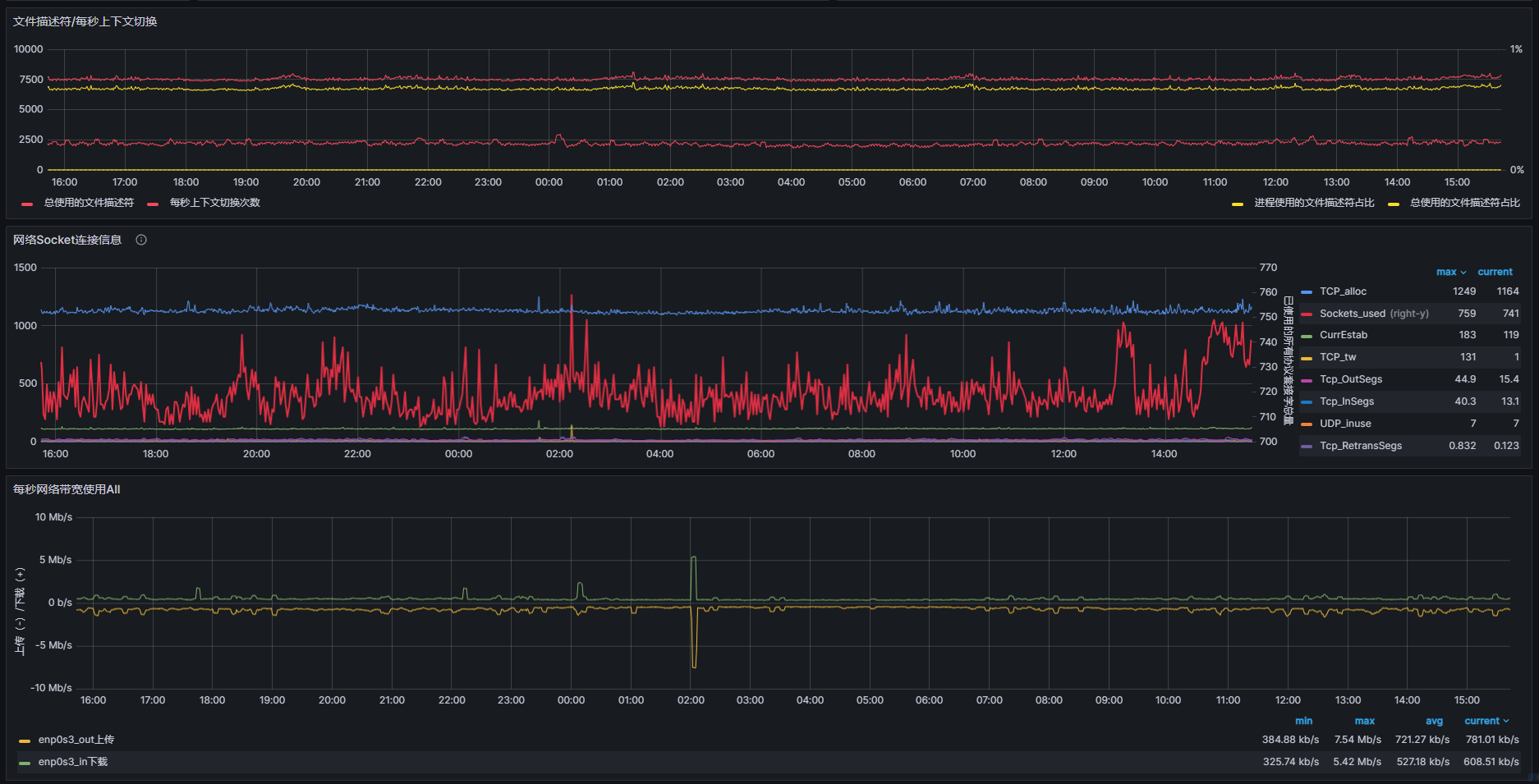
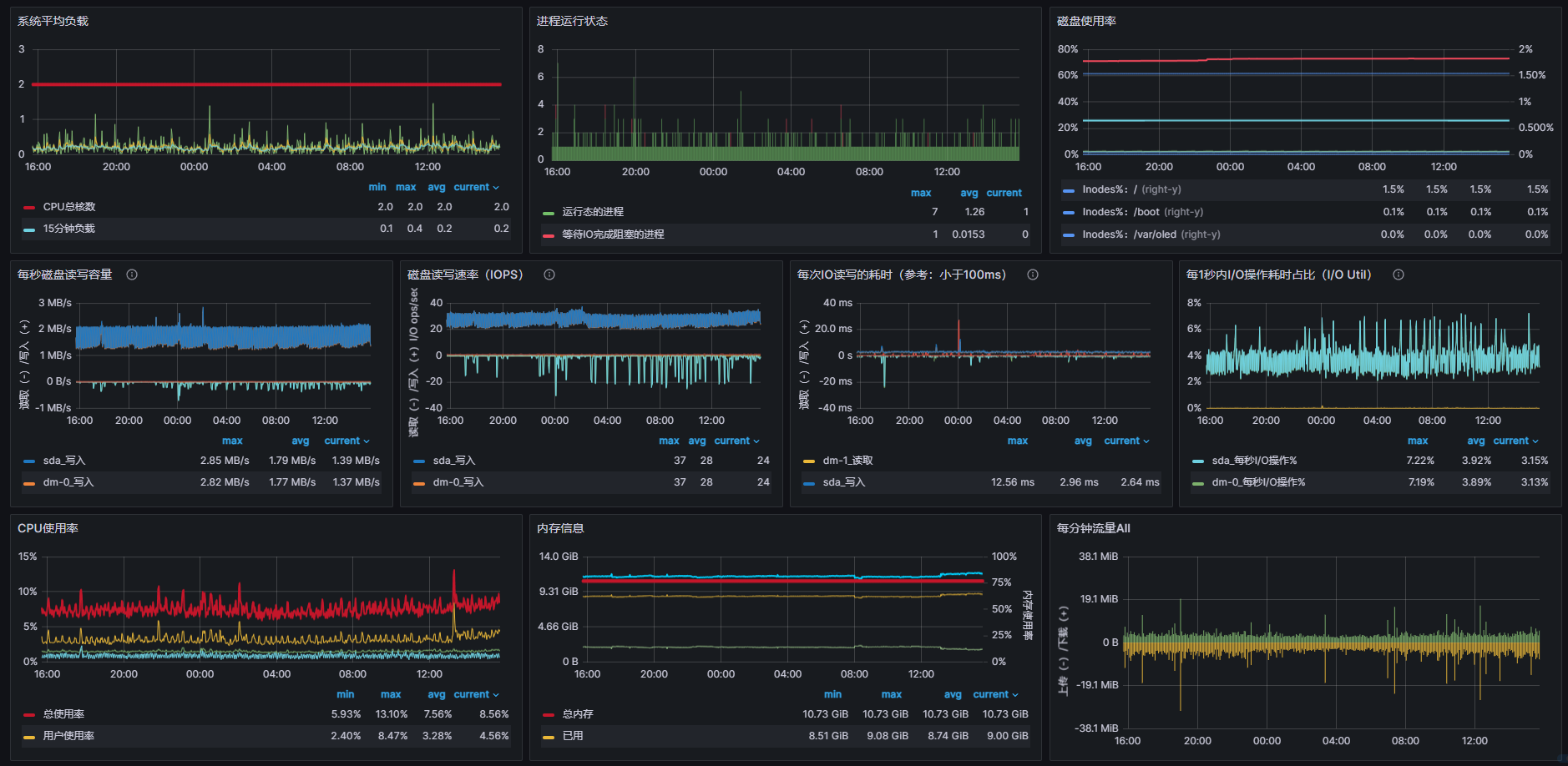
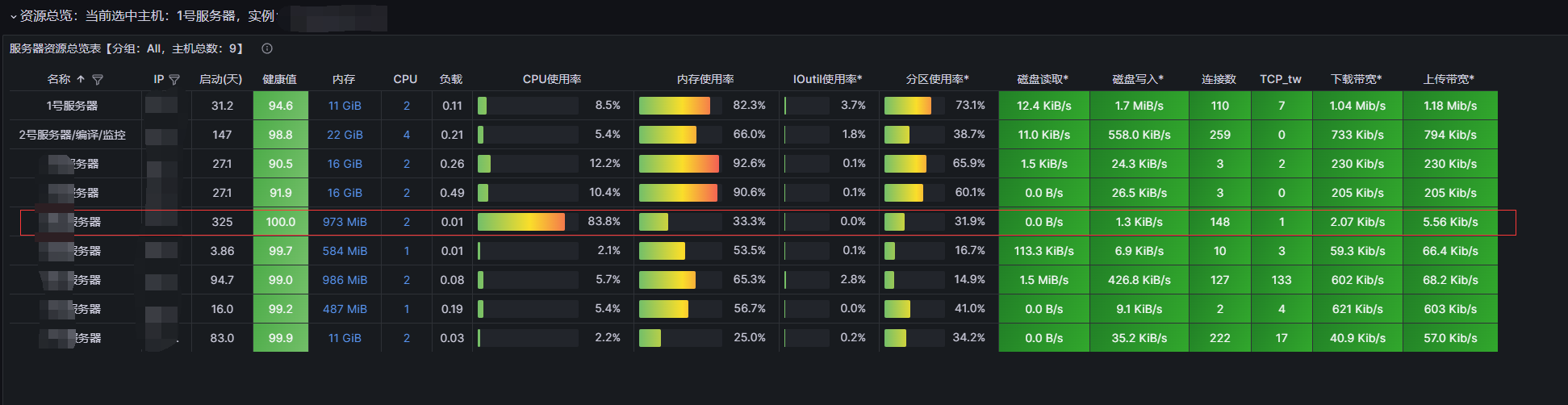
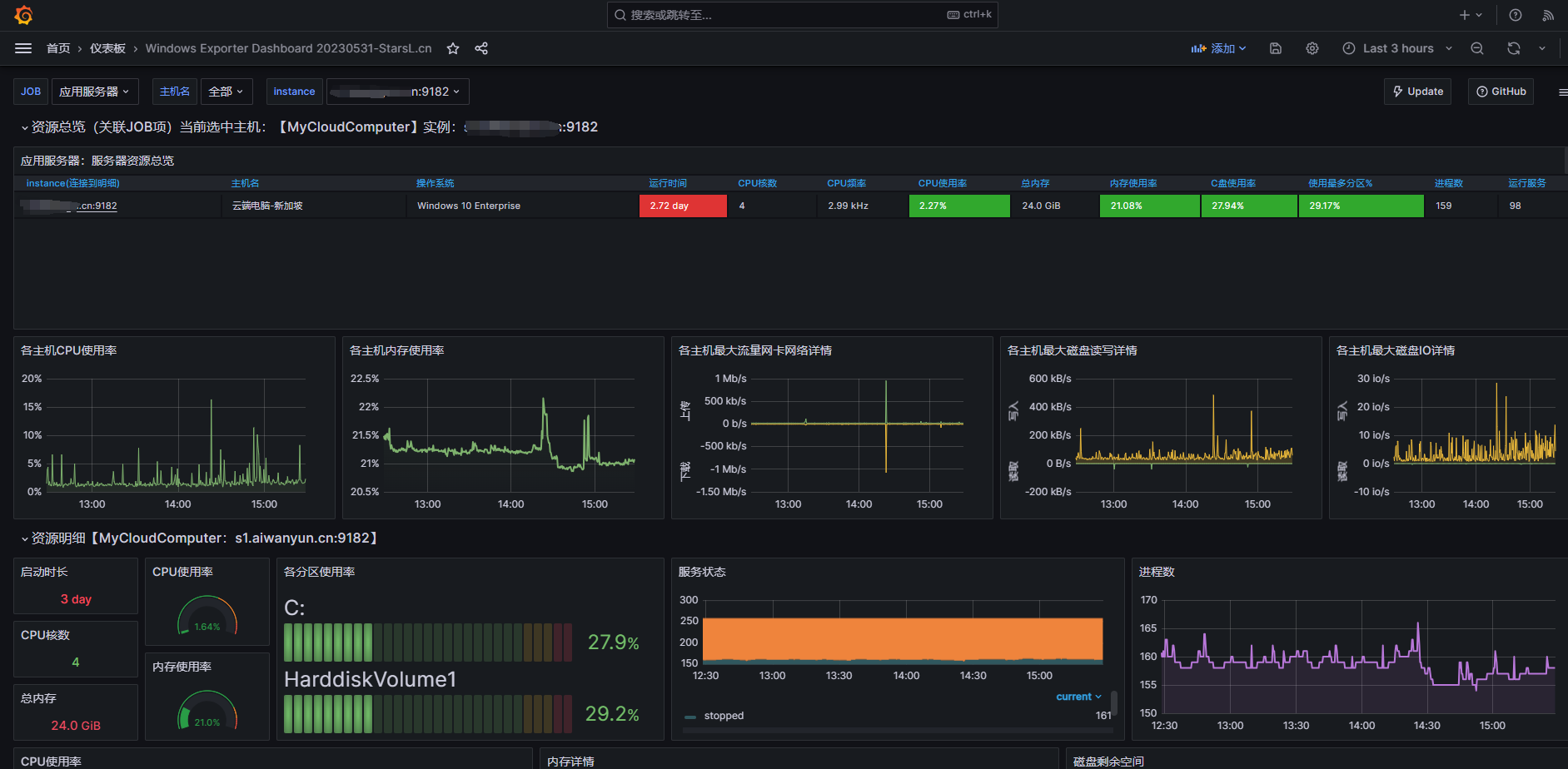
通过观察仪表盘,我们可以发现服务器中一些细微的问题,然后对其进行解决。
当然一些明显问题,直接通过观察健康值直接就可以分析出来。
alertmanager
这里是最后一个配置,当我们服务器出现异常警告的触发,这时候需要用到alertmanager进行邮件提醒,微信提醒,WebHook等等的推送操作,以便我们运维等人员及时发现并处理。
docker stop alertmanagerserver docker rm alertmanagerserver docker run -i --restart=always \ --name alertmanagerserver \ -p 9002:9093 \ -v /root/alertmanager/data:/alertmanager-data \ -v /root/alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml \ -d prom/alertmanager --config.file=/etc/alertmanager/alertmanager.yml --storage.path=/alertmanager-data/
9002:9093
9002:9093 内部端口是9003,通过宿主机的9002进行访问或者代理访问
/alertmanager-data
/alertmanager-data 数据目录,持久化
/etc/alertmanager/alertmanager.yml
/etc/alertmanager/alertmanager.yml 是推送相关的配置
global:
smtp_smarthost: mail.xxxxx.cn:587 #邮件服务器
smtp_from: noreply@xxxxx.cn #邮件发送者
smtp_auth_username: noreply@xxxxx.cn #账号
smtp_auth_identity: noreply@xxxxx.cn #账号
smtp_auth_password: xxxxxx #密码
route:
group_by: ['alertname']
receiver: 'default-receiver'
receivers:
- name: default-receiver
email_configs:
- to: xxxxx@qq.com #接收报警的邮箱
send_resolved: true
启动服务后,访问9002端口进行查看,如能进行访问,则部署成功。
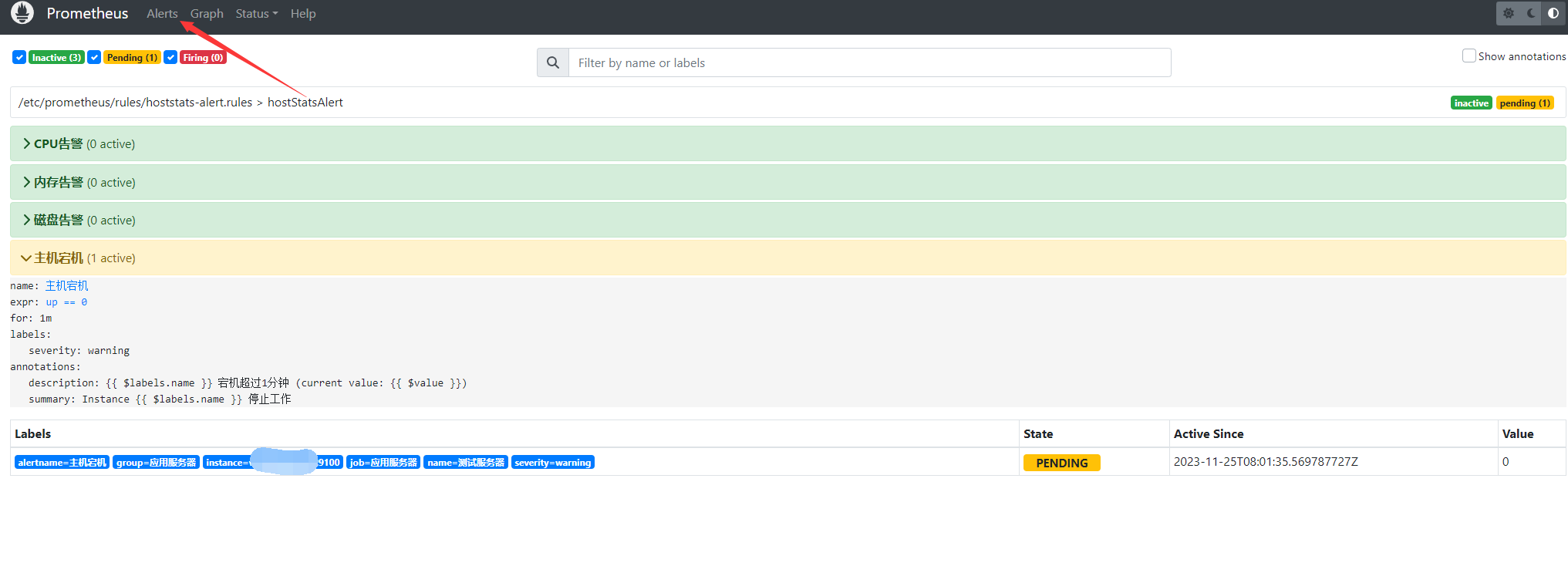
接下来我们尝试关闭否个服务器的采集或者持续使用CPU利用率进行测试验证。
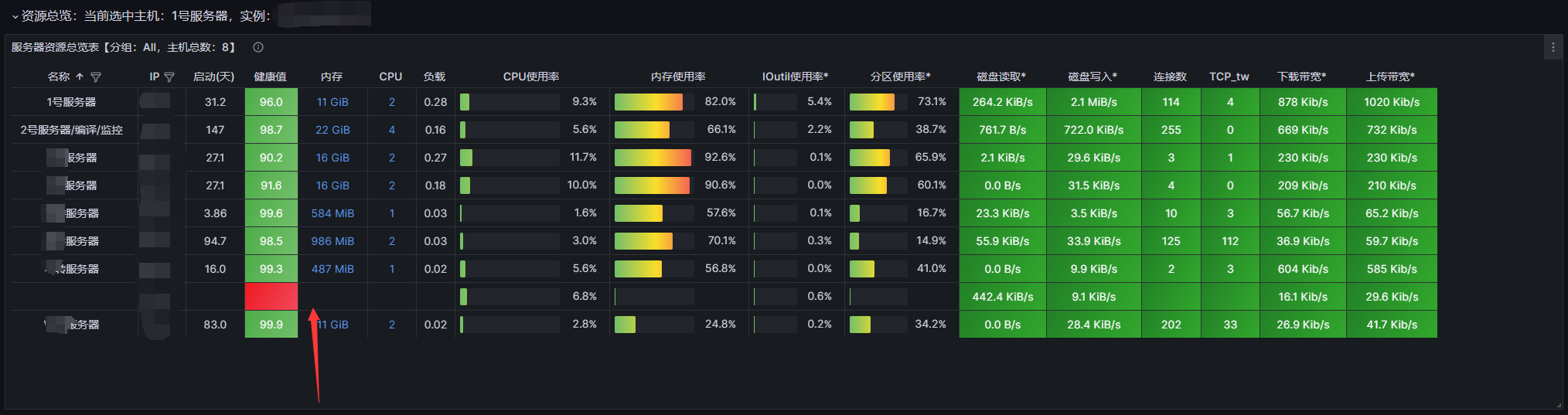
可以看到已经进入触发状态
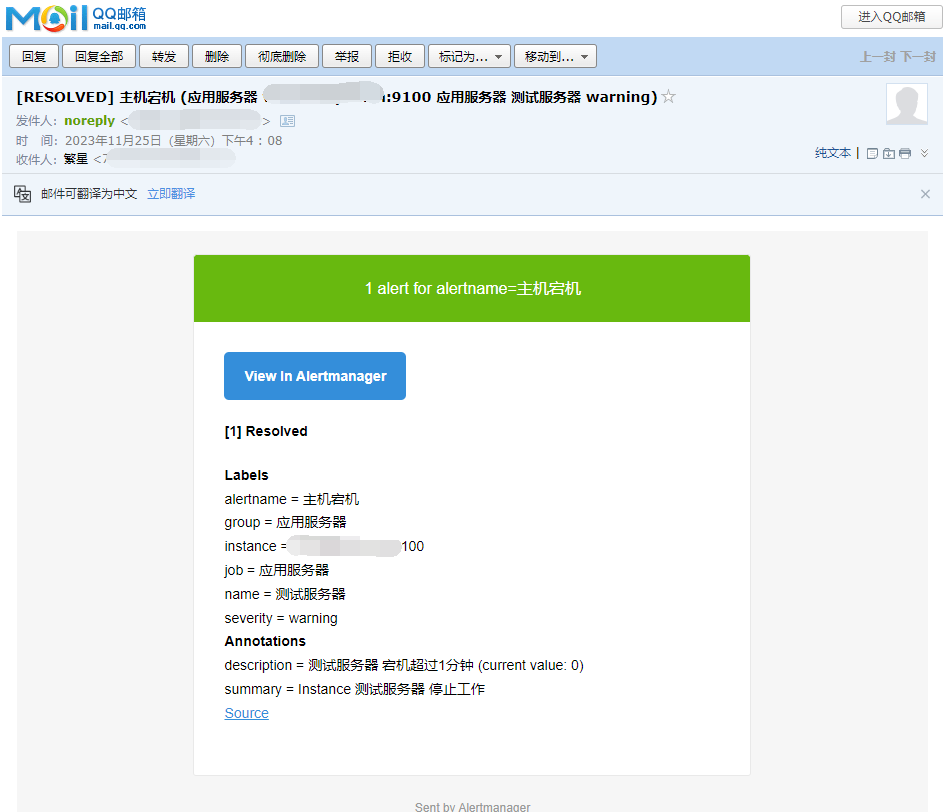
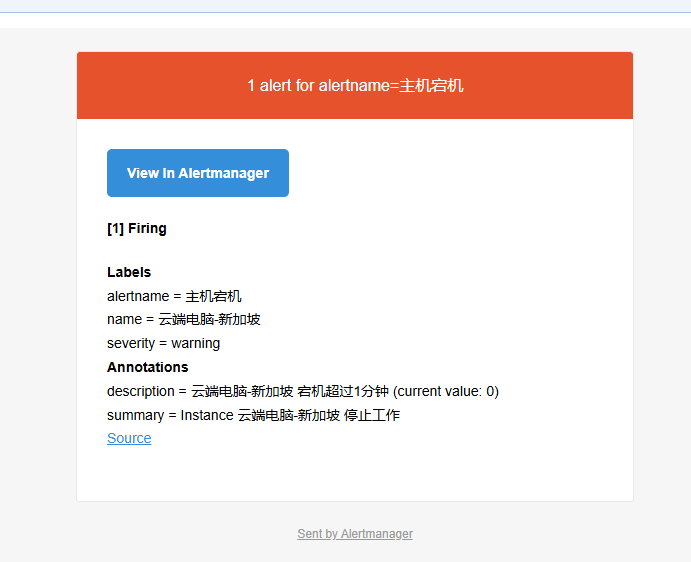
当然此刻已经收到邮件的告警提示
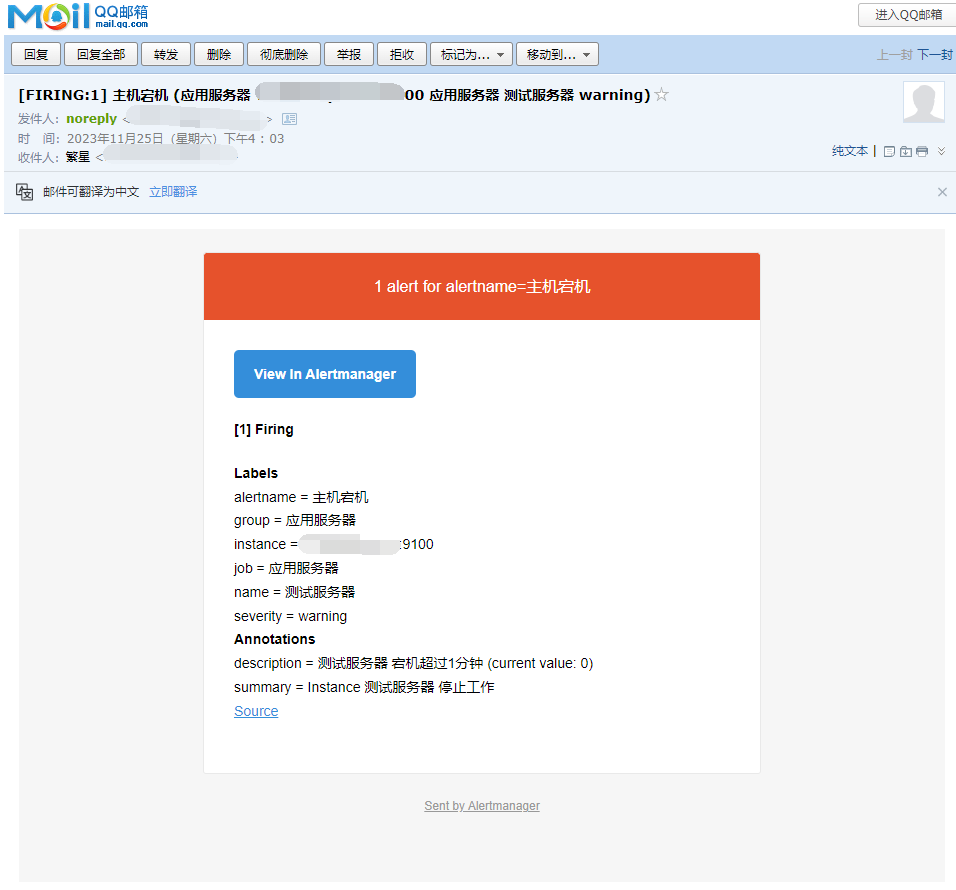
至此!我们整个流程已经走完,运维人员、开发人员等人也要开始炸锅了。哈哈
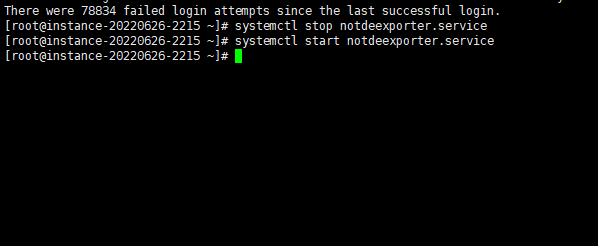
那么当我们重新启动采集服务后,恢复正常
Q&A
这里将会总结归纳日常的解决方案(待更新)
windows下如何设置监控指标呢?
开源项目地址:
https://github.com/prometheus-community/windows_exporter
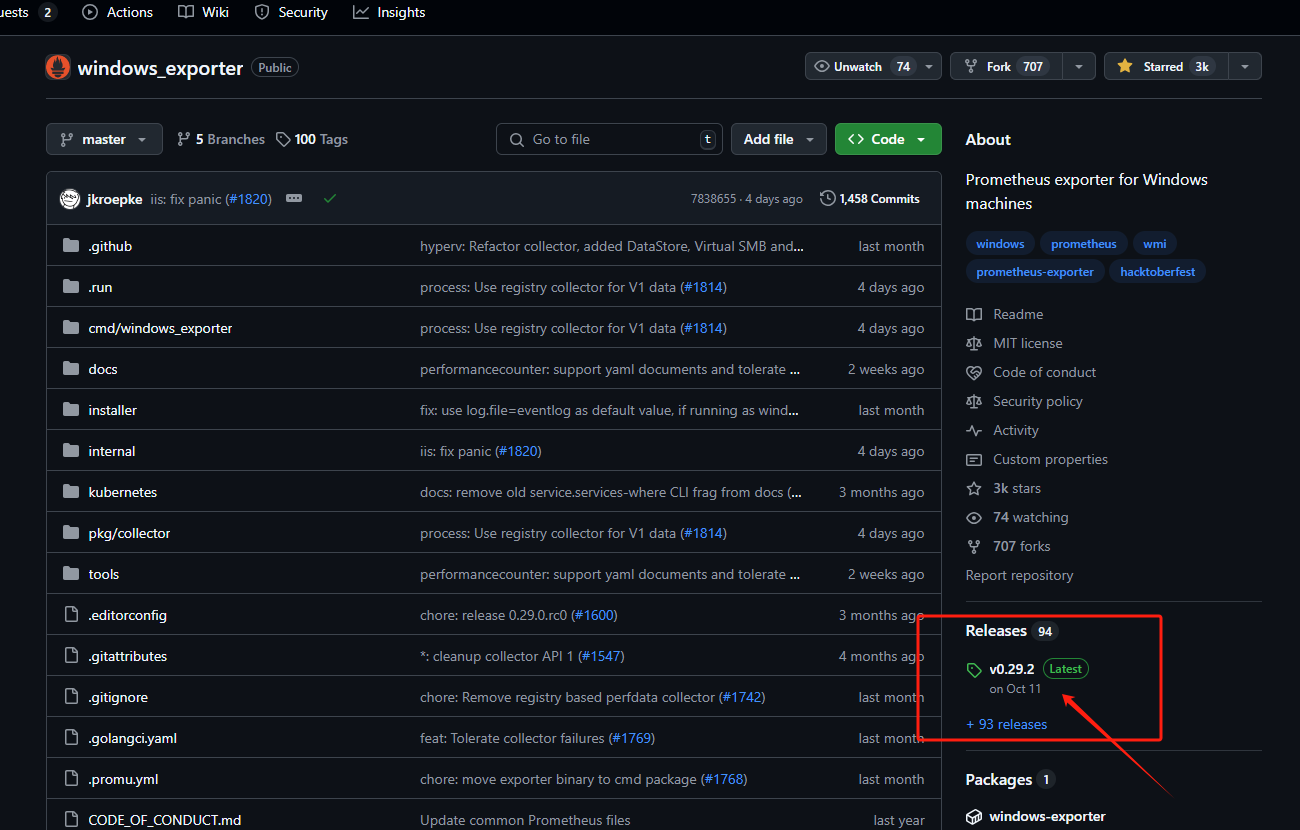
首先我们进入开源项目找到右下角的Release,这里是发布版文件,当然你也可以自己编译.
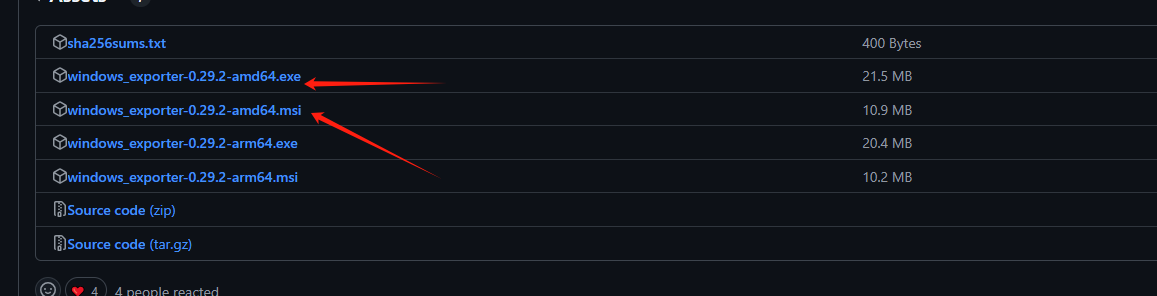
这里有两种格式
exe: 直接打开文件运行,但是不能后台自启动,需要自己配置自启
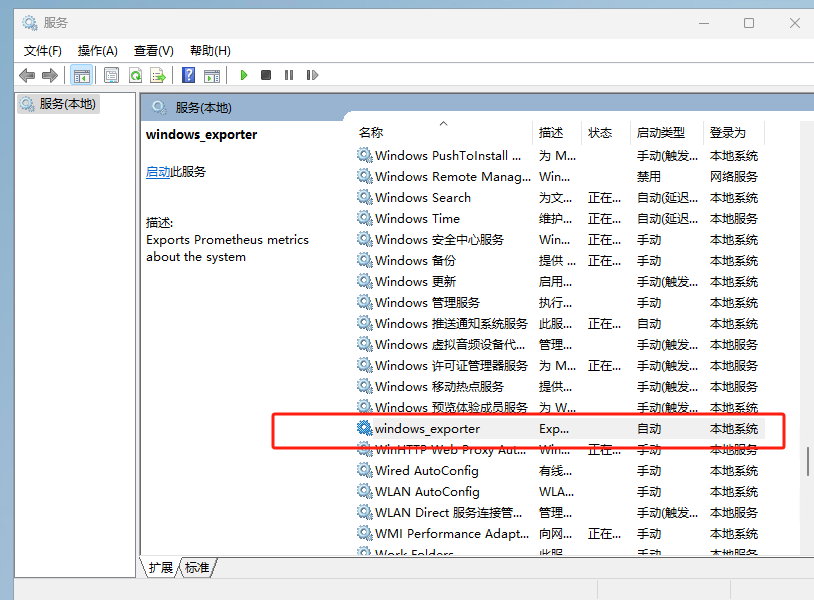
msi: 可直接双击安装后会自动以服务的方式运行,无需自己干预
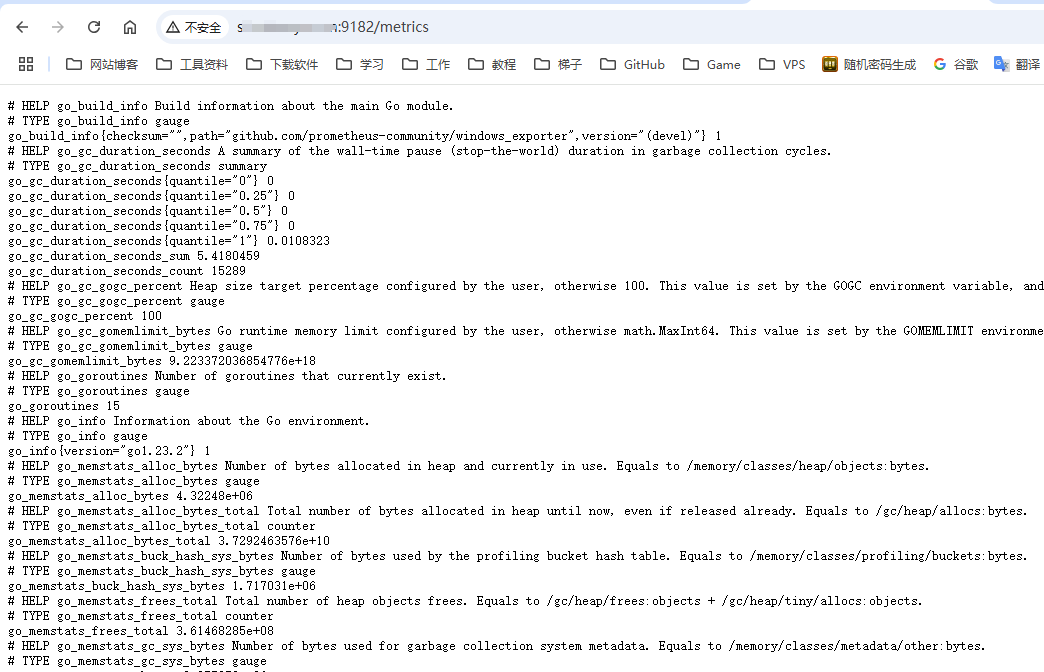
安装后本机直接访问9182端口加上metrics就可以直接访问到指标数据
接着导入指标面板
这里可以参考我使用的模板id:10467
进入面板后我们就可以观察到windows的指标数据了,当我们手动停止后台收集服务同样也会触发报警
至此,windows的指标手机已经完成.
good!!!